

Partition monitors
Monitor logical groups within tables/views so you can detect subtle quality issues and quickly diagnosis root cause
Monitors are great for detecting data quality issues across your tables and columns. However, monitors that operate on a whole table may miss subtle quality issues within a segment of your data.
For example, while the row count of your events table appears to be within a normal range, the row count for one or more specific event types could be below what’s expected — these subtle deviations may be small enough that they don’t affect the aggregate row count and therefore don’t cause the monitor to alert. This type of issue can occur with other types of monitors as well, e.g., freshness, distribution, nullness, etc.
Partition monitors allow data teams to define the logical groups (for example, aggregating by values in a dimension column) that make up a table and then apply monitors to those partitions. This means that data teams can monitor, say, the aggregate row count of a table as well as the row count for the logical partitions within that table.
Getting started
In order to configure partition monitors you’ll first need to navigate to the table that you want to target. You can do this by either searching for the table or navigating to a Connection and then drilling down to the table.
Once you’ve navigated to the table, you'll be able to create partition monitors through the pane on the right hand side.
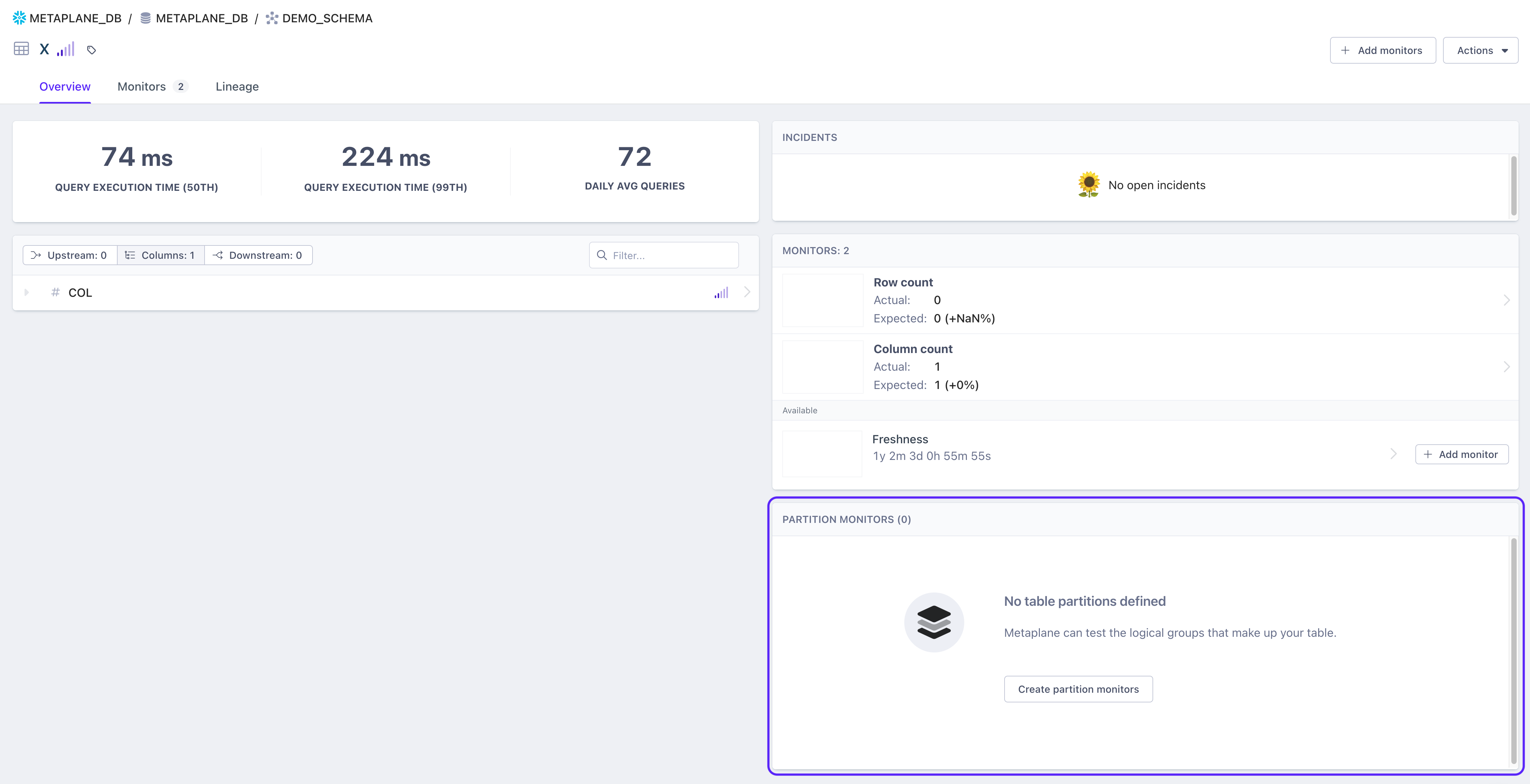
The creation of partition monitors involves 2 steps:
- Defining the partitions that make up the table
- Configuring the monitors that you want applied to the partitions
Defining partitions
Before Metaplane can add monitors to your table partitions, we first need to understand how to isolate the partitions that your team cares about.
After clicking “Create partition monitors” you’ll get greeted with the following dialog.

Group by a single column
Defining partitions by grouping by a single column is the simplest and most common strategy.
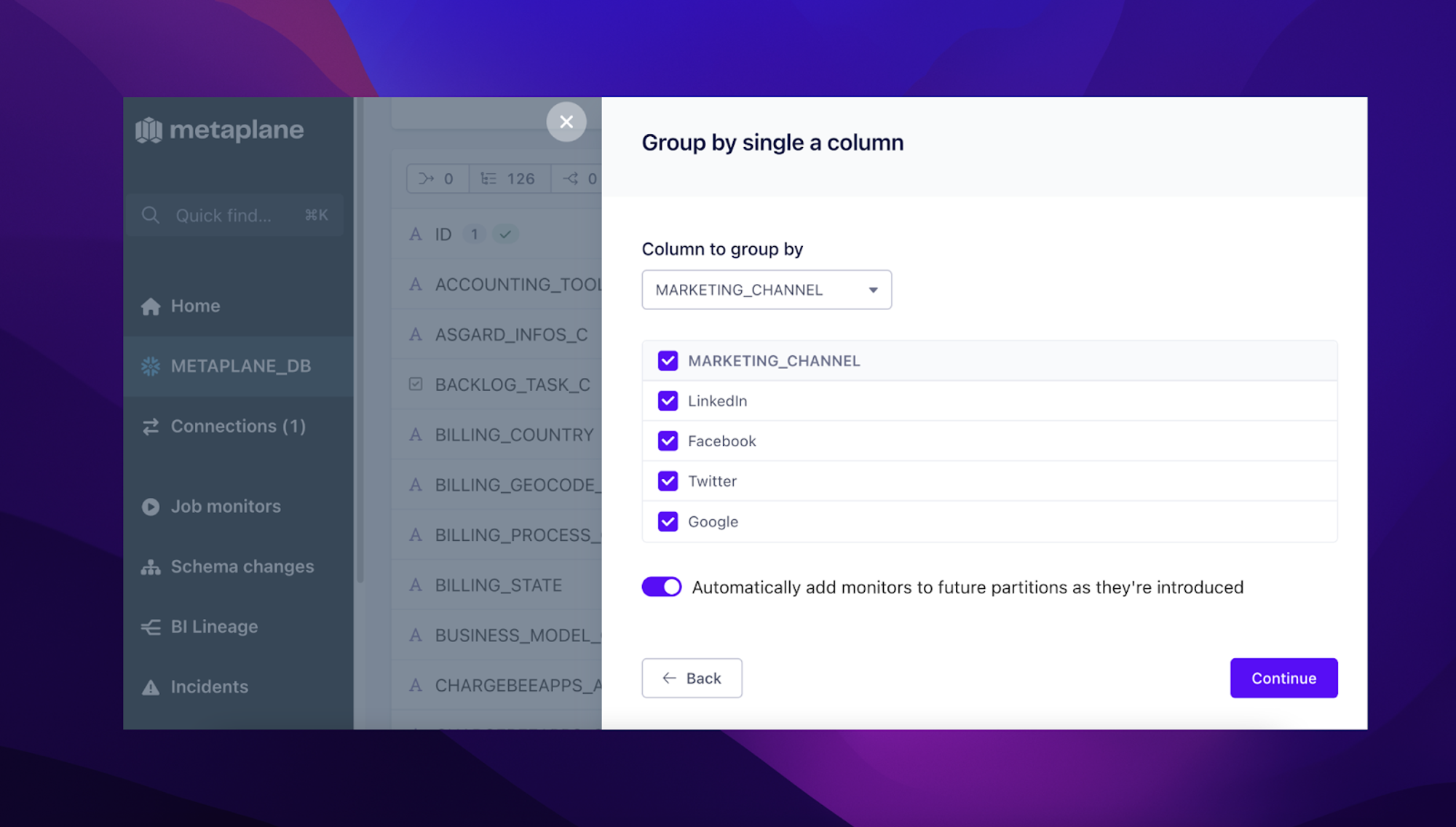
After selecting a column we’ll show you all of the related column values. These column values map to the set of partitions that will be monitored.
By default, Metaplane will treat the set of partitions as a ***dynamic*** set. That is, as new column values are introduced over time, Metaplane will automatically apply monitors to the respective partitions.
In some cases, only a strict set of partitions are important to your organization. In that case, you can choose to only select the column values that map to the important partitions. Alternatively, if you care about all of the displayed column values but don’t want Metaplane to automatically track new values, you can disable the automatic tracking using the switch below the table.
Custom SQL
In some cases, the set of partitions that are important to your organization can’t be isolated using a single column. Perhaps your partitions are best defined by grouping by multiple columns or by restricting the set using another column, e.g., using a date-based column. In that case, you should use custom SQL to define the partitions that matter most.
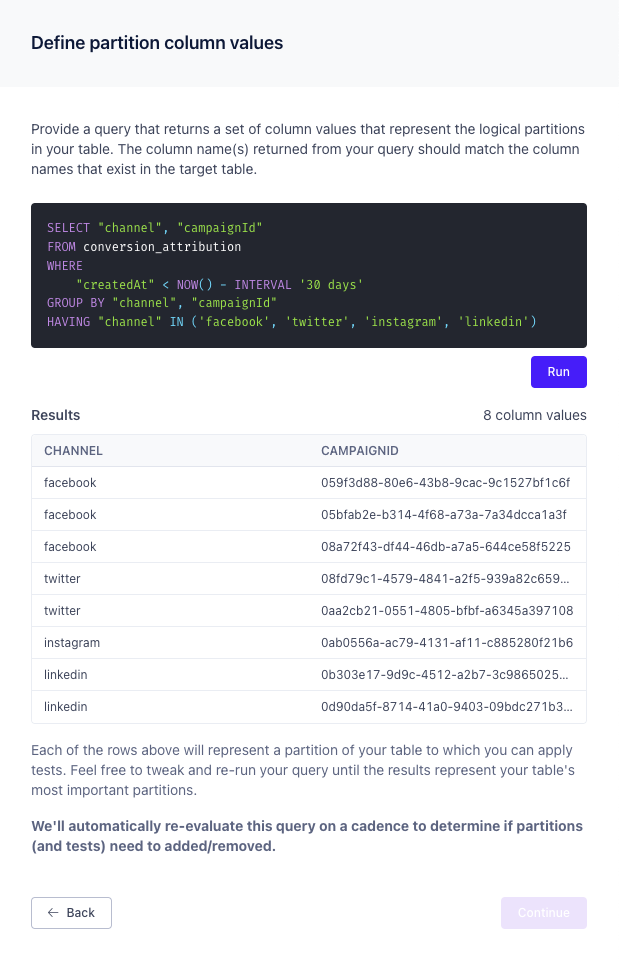
In the example above, the organization wants to add partition monitors to the partitions made by grouping by channel and campaignId. However, because campaigns are only run for 30 days, the rows are constrained by createdAt. Also, there are only 4 channel values that actually matter to the organization.
Although this example is a bit contrived, hopefully it shows the flexibility in choosing the custom SQL approach.
It’s important to note that the column names that are returned from your query must match the column names of the target table. Under the hood, we use the column names and values to constrain the rows that we monitor. Therefore, it wouldn’t make sense for a resulting column name to not match a column name in the table.
Next step
Once you’ve defined how to isolate your table’s partitions, you can now configure the set of monitors that you want applied to those partitions.
Configuring partition monitors
At this point Metaplane now understands the set of partitions that are important to your organization. Now, you’ll need to configure how you’d like to monitor those partitions.
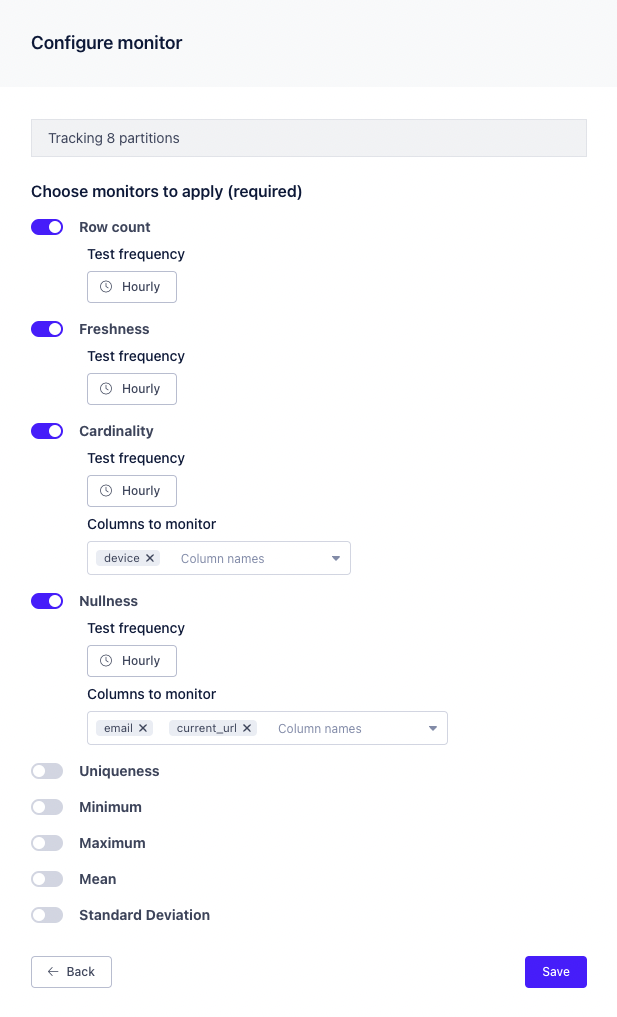
The monitors that you configure will get applied to the partitions that you defined the previous step. When/If new partitions are introduced over time then these same monitors will get applied to those as well. Similarly, Metaplane will automatically disable monitors for partitions that stop being included in the active set of partitions — this mostly applies to time sensitive custom-SQL-defined partitions.
Click “Save.”
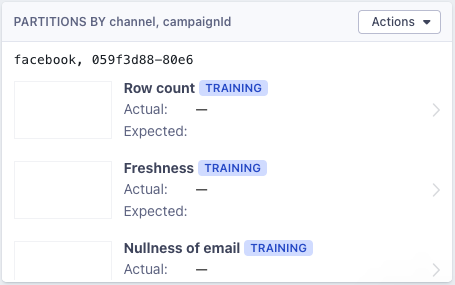
Once you’ve saved the partition monitor configuration, the partitions card on the table page will populate with both the partitions and monitors that you’ve configured.
Incident alerts related to specific partitions will be explicit about the affected partition.
Managing partitions
You can manage your partitions by updating the set of monitors applied to them or by completely removing the partitions. If—for example—you decide to turn off the nullness monitor then that means we’ll automatically disable all nullness on the partitions and prevent nullness from being added to future partitions.
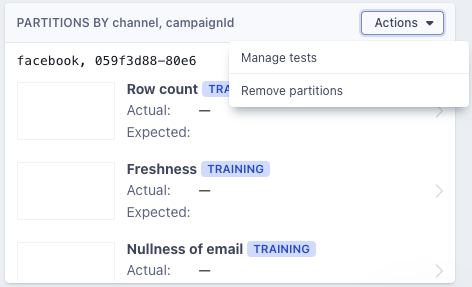
If you decide that you’d like to re-define the set of partitions, e.g., change the group by column or change the custom SQL, then you can remove the partitions and start fresh. Metaplane will keep your monitor history around in case your updated partition configuration yields the same partitions.
Use cases
There are use cases where partition monitors are a great fit for your monitoring needs and other cases where partition monitors are a bad fit.
Good fit
Generally, partition monitors are great when the set of partitions that you care about are relatively stable over time. For example, partitions by marketing channel, by event id, or some other column(s) with a relatively small and stable cardinality. Partitions that stay relevant for longer periods of time will give our model time to train and alert with confidence.
Bad fit
Generally, creating partitions using date-based columns won’t often work the way that you’d expect. It’s fine to use date-based columns in custom SQL to constrain the returned column values, but in most cases you won’t want to group your table by those columns for a couple of reasons:
- It takes our model roughly 3 days to train and every partition/monitor type combination gets its own monitor. Therefore, if you’re grouping by, say, a day-granularity timestamp (like midnight), then it’ll be at least 3 days before you’ll get alerted to an anomaly for a partition monitor created today. Depending on your specific use case, that may be 3 days too late.
- Depending on the granularity of the date-based column, you might end up with more partitions than actually matter to you.
That said, there are some exceptions. For example, if a partition by a date-based column is relevant for monitoring for an extended period of time, say at least 2 weeks, it could be reasonable to create that configuration. The longer the partition is relevant past 3 days, the more useful it’ll be to monitor it.
We’ve found that often times, what users actually want is for a monitor to operate on a rolling, date-column-based, window. For example, row count by the last 7 days. Fortunately, that’s a common use case to configure through other means.
We’re always happy to help guide our users on how to best monitor their data stack. If you have a specific use case that you’re unsure how to monitor, please reach out.
Updated about 1 year ago